from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import plot_tree
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=22)
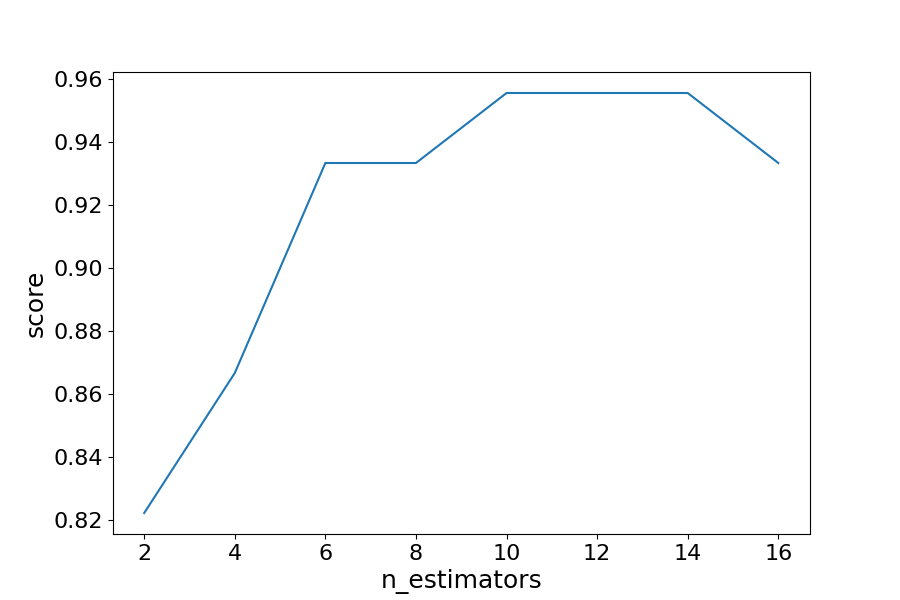
clf = BaggingClassifier(n_estimators=12, oob_score=True, random_state=22)
clf.fit(X_train, y_train)
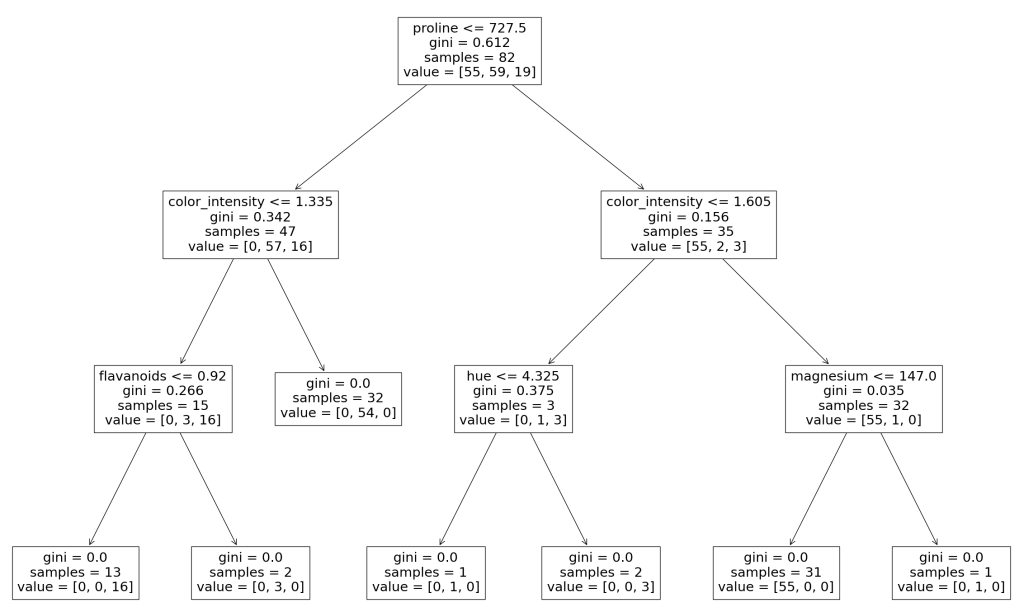
plt.figure(figsize=(30, 20))
plot_tree(clf.estimators_[0], feature_names=X.columns)






برای ارسال نظر لطفا ابتدا وارد حساب کاربری خود شوید. صفحه ورود و ثبت نام