K-means یک روش یادگیری غیرنظارتی برای خوشهبندی دادهها است. این الگوریتم به طور تکراری دادهها را به K خوشه تقسیم میکند تا واریانس در هر خوشه را کمینه کند.
در اینجا نحوه تخمین بهترین مقدار برای K با استفاده از روش آرنج (Elbow Method) و سپس استفاده از خوشهبندی K-means برای گروهبندی نقاط داده به خوشهها را نشان میدهیم.
چگونه کار میکند؟
تخصیص اولیه: هر نقطه داده به طور تصادفی به یکی از K خوشهها تخصیص داده میشود.
محاسبه مرکز خوشه: مرکز هر خوشه محاسبه میشود.
تخصیص مجدد: هر نقطه داده به خوشهای با نزدیکترین مرکز تخصیص داده میشود.
تکرار: این فرآیند تا زمانی که تخصیص خوشهها برای هر نقطه داده تغییر نکند، تکرار میشود.
روش آرنج (Elbow Method)
برای انتخاب مقدار مناسب K، از روش آرنج استفاده میکنیم که به ما امکان میدهد اینرشیای خوشهها را برای مقادیر مختلف K رسم کنیم و نقطهای که در آن کاهش خطی آغاز میشود را شناسایی کنیم. این نقطه به عنوان “آرنج” شناخته میشود و معمولاً بهترین مقدار برای K است.
مثال عملی
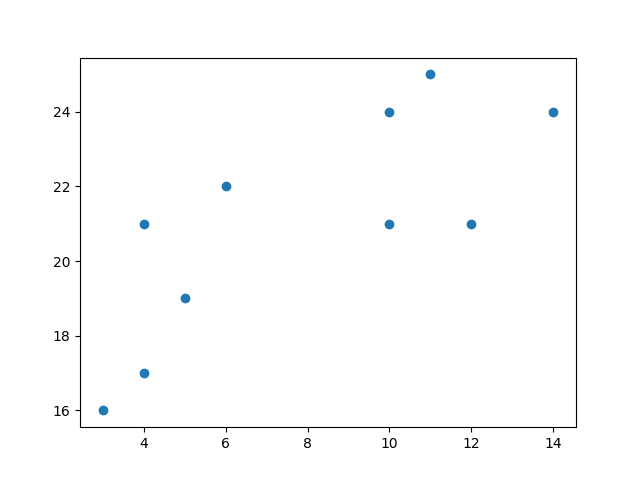
نمایش دادهها
ابتدا دادههای خود را به صورت نمودار پراکندگی نمایش میدهیم:
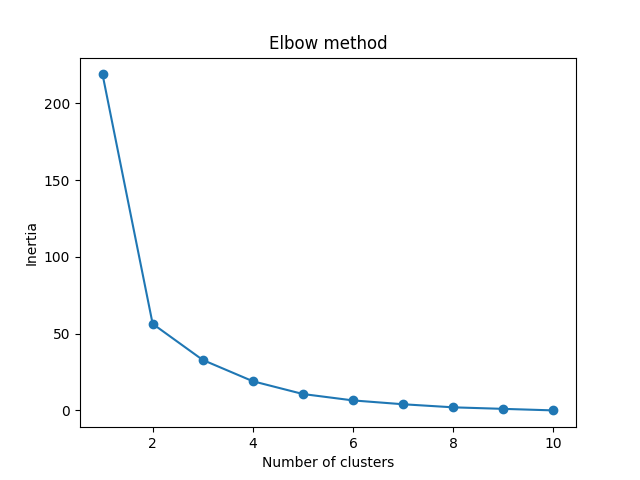
پیدا کردن بهترین K: برای یافتن بهترین مقدار K، الگوریتم K-means را برای محدودهای از مقادیر ممکن اجرا کرده و اینرشیای خوشهها را برای هر مقدار رسم میکنیم:
inertias = []
for i in range(1, 11):
kmeans = KMeans(n_clusters=i)
kmeans.fit(data)
inertias.append(kmeans.inertia_)
plt.plot(range(1, 11), inertias, marker='o')
plt.title('Elbow Method')
plt.xlabel('Number of clusters')
plt.ylabel('Inertia')
plt.show()
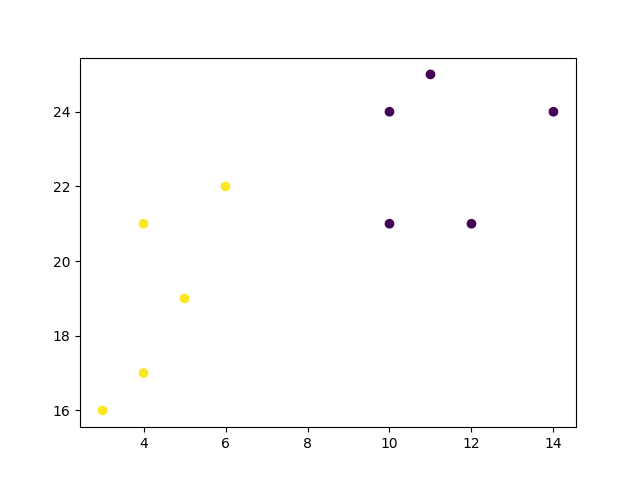
نتیجه: میتوانیم ببینیم که “آرنج” در نمودار (جایی که اینرشیای خوشهها به صورت خطی کاهش مییابد) در
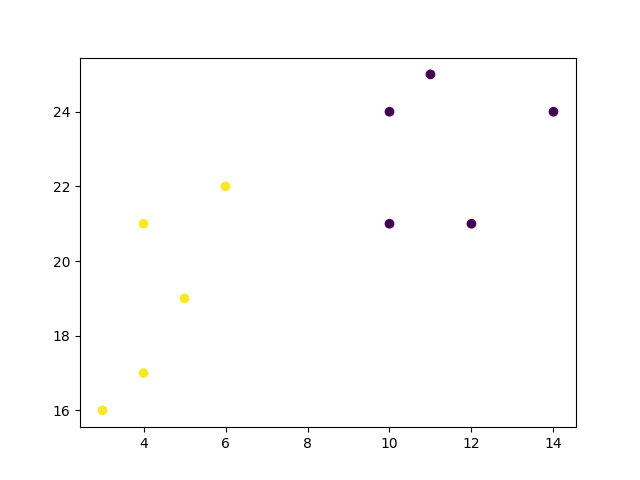
K=2 است. سپس الگوریتم K-means را دوباره با این مقدار اجرا کرده و خوشههای مختلف دادهها را رسم میکنیم:
kmeans = KMeans(n_clusters=2)
kmeans.fit(data)
plt.scatter(x, y, c=kmeans.labels_)
plt.show()






برای ارسال نظر لطفا ابتدا وارد حساب کاربری خود شوید. صفحه ورود و ثبت نام