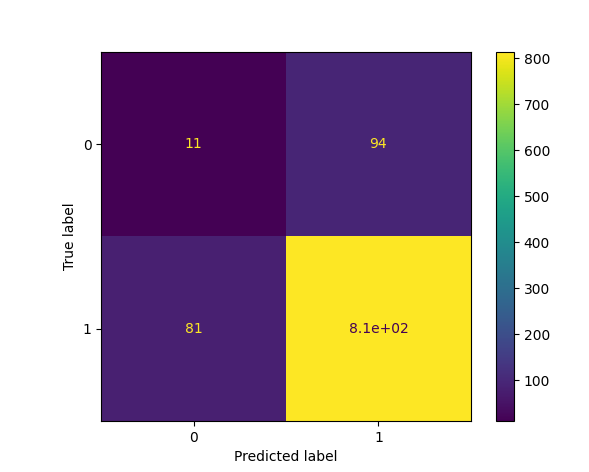
import numpy
from sklearn import metrics
import matplotlib.pyplot as plt
# تولید مقادیر واقعی و پیشبینی شده
actual = numpy.random.binomial(1, 0.9, size=1000)
predicted = numpy.random.binomial(1, 0.9, size=1000)
# ایجاد ماتریس اشتباه
confusion_matrix = metrics.confusion_matrix(actual, predicted)
# تبدیل به نمایش تصویری
cm_display = metrics.ConfusionMatrixDisplay(confusion_matrix=confusion_matrix, display_labels=[0, 1])
# نمایش تصویری
cm_display.plot()
plt.show()






برای ارسال نظر لطفا ابتدا وارد حساب کاربری خود شوید. صفحه ورود و ثبت نام